Logical Architecture
Flow
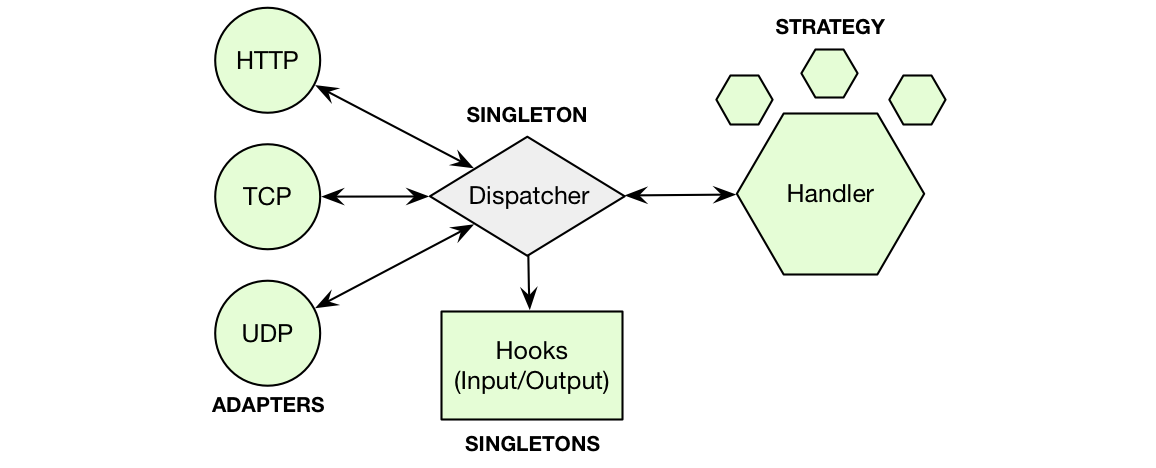
- Data pours in from multiple sources through the docks. Each dock accounts for a single protocol and listens to one port.
- The dock parses the data and converts it to a plain javascript object.
- The dock sends it to the dispatcher.
- The dispatcher looks at the tag property and routes the data to the right handler.
- The input hooks (read-only middlewares) can access the data and do stuff with it, but they can't modify it.
- The handler processes the data, persisting it, redirecting it, etc.
- If the handler generates a response, it goes to the dispatcher. If there's no response, the process ends here.
- The output hooks can get their hands on the response and do stuff with it, but they can't modify it.
- Then the dispatcher gets the response and routes it to the right dock.
- The dock sends it back to the original device.
Tags
The tag is the first portion of the message sent by a device. A single data packet must contain a tag, and no more than one. The message tag defines a data flow. And each data flow is put together by stacking components on a pipeline. It is akin to the request/response cycle in a regular web application. A single data flow is made up of two phases:
Input flow
Represents the path a piece of raw data takes from the device to a single handler. Input hooks are executed in parallel.
Output flow
The response making its way back to the original device. Output hooks are executed in parallel. This flow is dependent on the existence of a response; if the handler generates no response, the input flow is all there is.
Components
Docks, hooks and handlers can be third-party packages or custom code. They should all be hot-swappable, and reload automatically on change without restarting Iris.
Parsers
While the dock base class will include a generic parser (with configurable data and tag delimiters), it must be possible to pass in a custom parser function.
Threads
Iris must span on boot a fixed, configurable number of threads that kick in and handle the data after the dispatcher routes it. Each data flow must be managed by the same thread from this point onwards. This allows for parallel processing and increases stability and data processing speed.
Physical Architecture

Iris is designed to sit right in front of the data generating devices. Once the raw data has been processed, Iris can pass it on to other services.
Stack
Iris uses no database by default, and has no UI. Regarding reverse proxies, Iris should access the system ports directly. Though it should be possible to run an array of Iris instances behind a load balancer.
- Node.js 6.5.0+